PEG and Rust
2023-05-16
For the first post here, nothing better than writing a bit about the tool I created to build this static website.
During the end of the pandemic, I had the opportunity to take the “Building a Programming Language” by Roberto Ierusalimschy (creator of the Lua programming language). He mainly talked about PEGs, more specifically about LPEG (a Lua library he created). Since then I wanted to play with PEG using Rust and the TinyLang is the result of it.
First things first, before I talk about PEG in Rust (and my TinyLang), let’s go through the basics.
How programming languages are born
Take a look at the main components of an Interpreted Programming Language:
- Tokenizer (Lexical Analysis): scans the source code and breaks it down into meaningful tokens. Tokens represent the smallest units of the language, such as keywords, identifiers, literals, and operators.
- Parser: Takes the tokens generated by the Tokenizer and constructs a parse tree or an abstract syntax tree (AST). The parse tree represents the structure of the program based on the grammar rules of your language.
- Interpreter (tree-walk Interpreter): Walks the AST and handles the runtime environment, including memory management, variable tracking, and control flow handling.
Parsing expression grammar (PEG)
In computer science, a parsing expression grammar (PEG) is a type of analytic formal grammar, i.e. it describes a formal language in terms of a set of rules for recognizing strings in the language. Syntactically, PEGs also look similar to context-free grammars (CFGs), but they have a different interpretation: the choice operator selects the first match in PEG, while it is ambiguous in CFG. This is closer to how string recognition tends to be done in practice, e.g. by a recursive descent parser.
Unlike CFGs, PEGs cannot be ambiguous; a string has exactly one valid parse tree or none. PEGs are well-suited to parsing computer languages.
The Wikipedia description of it does not seem easy to parse (pun intended), it basically defines PEGs in contrast with CFGs.
Both PEG and CFG can be used to create parsers for programming languages. The main difference is that PEG cannot be ambiguous, so in theory you can easily read the PEG file and understand the grammar.
Let’s take a look at PEST a PEG Rust Library with an example from their documentation. The following is an example of a grammar for a list of alpha-numeric identifiers where the first identifier does not start with a digit:
alpha = { 'a'..'z' | 'A'..'Z' }
digit = { '0'..'9' }
ident = { (alpha | digit)+ }
ident_list = _{ !digit ~ ident ~ (" " ~ ident)+ }
Forget about the _ for now. The first rule defines alpha characters and will match with anything between a and z and A and Z. The second match digits following the same approach.
The third rule is more interesting it matches alpha or digit ONE or more times (the +) If we wanted to match ZERO or more we could replace it with *. The rule ident_list matches something that is not (!) a digit followed (~) by an ident followed by a “space and ident” one or more times.
If we try to match against a 1 b, it will generate the following:
- ident > alpha: "a"
- ident > digit: "1"
- ident > alpha: "b"
You may notice that we do not have any ident_list and the reason is that the _ is a modifier to make it a “silent rule”, basically a rule that will not be in our final AST.
The output generated looks like the following image where all the idents are on the same iterable data structure:
.png)
TinyLang
Ok, so let’s head back to my side project. TinyLang is not really a general-purpose language, but a template language. The main goal is to define based on templates how a static website will look like. My main needs are:
- Anything that is pure HTML should just be copied over
- I need a way to “print” variable values
- I need flow control so I can hide sections depending on variable values and repeat sections based on collections
- I need to render partials.
Let’s forget the fourth need for now. If you take a look at my pest file (where I define the grammar for the language) you are going to see that the entry point of my grammar (rule g) is the following:
g = ${ (dynamic | print | invalid | html)* }
The $ makes the rule a compound atomic. I needed it because by default PEST would consider that each rule is separated by space. And would “eat” a space in some cases. I will detail this more later.
Also, remember from our definition of PEG, that the order of the rules is important! If an input matches the first rule, the PEG library won’t try to match it against the other rules to see if they “match more”. In our case, the htmlrule is:
html = !{ (ANY ~ (!("{{" | "{%") ~ ANY)*) ~ NON_SILENT_WHITESPACE** }
You can see that we match against ANY character, if the HTML rule was the first it could crash with other rules. One interesting point is that the rule will match any character until it finds a {{ or a {% but originally the rule was something like html = { ANY }. That would create a token for each character and slow down the whole process. And of course, the order in which HTML appears on the g rule would matter even more since would match everything without consideration for the other rules.
The dynamic handles my third need (the control flow) and the commands should be inside a {% %} . The print handles my second need and whatever I want to print should be inside {{ }}. The invalid is actually a hack to handle invalid inputs, where you add a {% or a {{ and never close it. I will probably remove it at a later stage. The final rule is HTML which is basically anything.
That grammar should output things like:
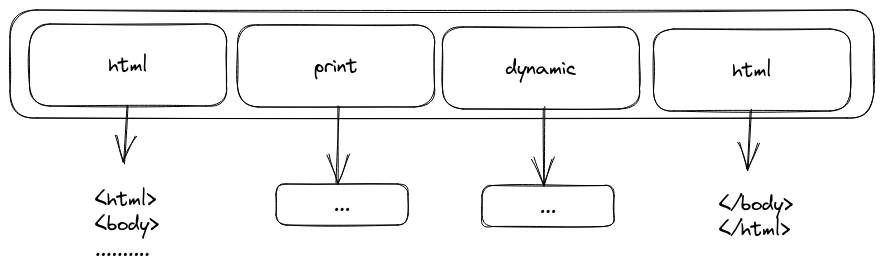
So each HTML node just points to a big &str, while print and dynamic point to more complex data structures, since they should handle expressions such as a + 4 + 5 + my_object.property + func_call().
So in theory we could walk the main iterable structure and handle each node with a special function. Rust is great for that! Something like:
use pest::Parser;
#[derive(Parser)]
#[grammar = "../grammar/template_lang.pest"]
struct TemplateLangParser;
pub fn eval(input: &str) -> Result<String, ParseError> {
let pairs = parse(input)?.next().unwrap().into_inner();
let mut output = String::new();
for pair in pairs {
let current_output = match pair.as_rule() {
Rule::html => visit_html(pair)?,
Rule::print => visit_print(pair.into_inner())?,
Rule::dynamic => visit_dynamic(pair.into_inner())?,
Rule::invalid => visit_invalid(pair.into_inner())?,
_ => unreachable!(),
};
output.push_str(¤t_output);
}
Ok(output)
}
pub fn parse(input: &str) -> Result<Pairs<Rule>, ParseError> {
// this is g which contains children which are
// either html chars, print statments or dynamic statements
TemplateLangParser::parse(Rule::g, input).map_err(|e| {
ParseError::Generic(e.to_string())
})
}
Thanks to Rust enums and the PEST library we could write something this simple to make everything work. Each of the visit_* methods would also need to have a match against the rules they are supposed to handle and thanks to the power of abstraction we would have our language done.
But TinyLang has one implementation detail that complicates our life. If our grammar would output something like:
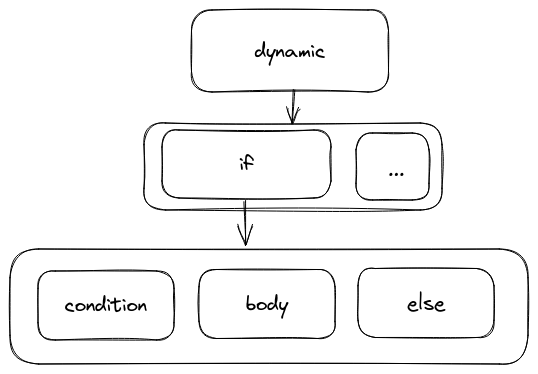
That initial design would work almost out of the box. When processing a dynamic node we would match against the possible rules (if, for and so on). For the if node, we evaluate its first child, if it’s true, we execute/output the second child, if not we execute/output the third (if exists).
But for our grammar will really output the following:
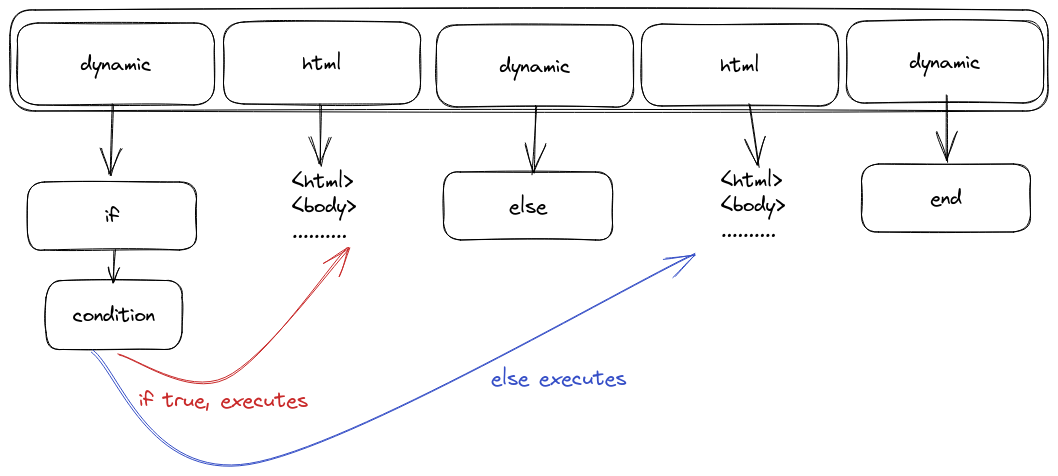
This complicates a bit more things, as we walk through the main iterable structure, we also need to keep track of things like: if, for and so on. Which “uglifies” the code a bit, but the concept is still the same.
And of course, I could modify the grammar to output the previous solution (and probably I will at some point in the future).
State and function calls
The template language also needs a state. Because we want to setup common variables and collections to use it inside the templates. One common example is looping through all the posts collections in order to show their titles on index.
To make it more simple, users are not allowed to assign new values to variables. Well, not explicitly anyway, because the for loop will create a variable to allow things like:
{% for item in colection %}
{{item}}
{% end %}
Another simplification is that we have only a global state, meaning we don't need to worry about local variables on different scopes. This mostly makes sense because users cannot assign new values to variables anyway.
This global state is basically a map between variable names and values. That is why TinyLang uses a HashMap<String, ???> as state. The keys are the variable names, but what about the values? What should it be? In theory, we could just say that any valid Rust value is also valid, but the implementation of TinyLang and Rust would be much more coupled than it already is. Instead, we use an enum TinyLangType, which basically represents any possible value inside TinyLang world.
type State = HashMap<String, TinyLangType>
pub enum TinyLangType {
String(String),
/// any integer or float is represented as a f64
Numeric(f64),
Bool(bool),
/// Any function will receive the parameters as an array
/// so sum(1, 2, 3, 4) will be transformed as sum(vec![1, 2, 3, 4])
/// all functions must return a TinyLangType, if yours does not return
/// anything use the TinyLangType::Nil type.
/// Users cannot declare functions inside the template file.
/// The function also receives the global state
Function(Function),
/// Represents a Vector to be iterated using the for loop
/// it cannot be created inside the template file.
Vec(Vec<TinyLangType>),
/// Each instance of an object has their own "vtable"
Object(State),
Nil,
}
Thanks to the traits in the Rust ecosystem we can make it easier for users to transform Rust types into TinyLangTypes:
impl From<&str> for TinyLangType {
fn from(value: &str) -> Self {
Self::String(value.to_string())
}
}
Allowing us to write:
let a_tinylang_string: TinyLangType = "yay, super simple".into();
TinyLang also supports function calls such as {% my_func_call('abc') %}. I won't enter into much details here, but this works by packing all parameters as an array of TinyLangType and calling a function declared on the Rust side.
Code
With all this information, I think is possible to navigate the code and understand what is going on, even if you never used PEST or PEGs before. I chose PEST because it seemed the simplest library out there and the documentation was good enough. I hope this post contributes somehow to people that want to use PEST, but wants a bigger example than the one in their book.
The code is available at https://github.com/era/tinylang. And since it's so easy to compile to WebAssembly, I also made a website where you can try it out https://tinylang.elias.tools/.
That is it
I hope you enjoyed this trip around my pet project. At the moment I’m really enthusiastic about Rust programming language and I’m looking for projects to collaborate with. If you want help with your side/pet project, let me know on Twitter, and feel free to DM me :), or just email me rust@{{this_domain}}.
If you are interested on TinyLang, you can check it on Github.
The code for this website is at Github as well.
Thank you for reading,