Data Federation and Trustfall
2023-08-29
Data federation is an approach that consolidates data from multiple sources into a single virtual view. This method eradicates data duplication and the formation of data silos, currently drawing significant attention from industry players like Databricks, Starburst, and major cloud providers such as AWS (Athena and Redshift Spectrum). But why is this trend gaining momentum?
Daniel Abadi says in his post about the subject “Thirty years ago it was already commonplace for large businesses to have hundreds — even thousands of different database instances managing data from the variety of different applications running at that business”. This situation resulted in the proliferation of data silos, complicating the retrieval of answers that required combining information from various sources.
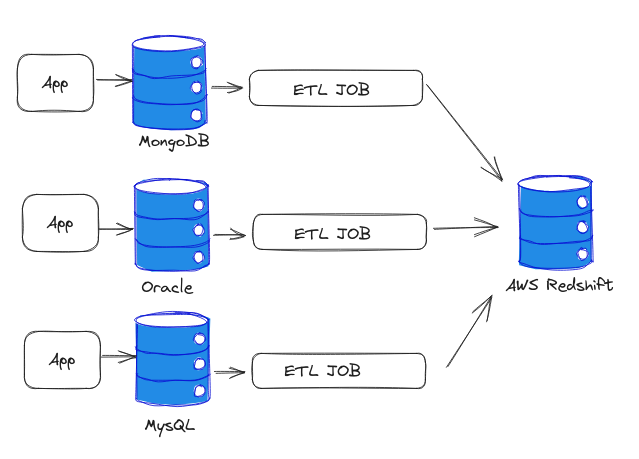
Traditionally, organizations addressed this challenge by building ETL (extract, transform, load) pipelines to centralize data into a single warehouse, such as AWS Redshift (where I had the opportunity to work during my time at Amazon :P). However, this approach introduces friction, requiring ongoing pipeline maintenance. Moreover, running these jobs continuously may impact application performance, leading many to schedule batch jobs at night, resulting in a centralized view that is at least one day delayed.
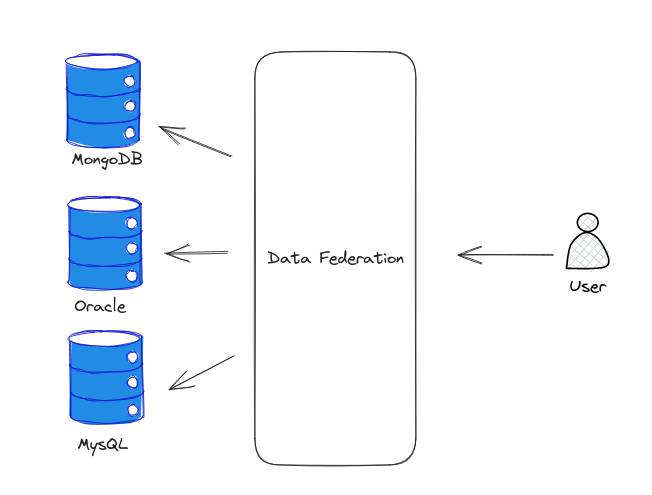
A contrasting approach involves employing a data federation system capable of translating user requests across different data sources. This becomes especially valuable when merging data from different sources.
This methodology enables the retrieval of more "fresh" data, querying directly from where it resides. A practical example involves using Presto to query diverse data sources.
Digging into the Presto architecture, outlined in the Presto white paper, the coordinator manages complex tasks like optimizing query plans, while the optimizer/planner transforms SQL queries (SQL is a declarative language, so it does not tell HOW things should be executed, but WHAT the user wants) into executable plans. It will also break the request into smaller tasks and split it between the workers so it can be run in parallel. Presto's ability to return results incrementally, rather than waiting for completion, adds to its appeal.
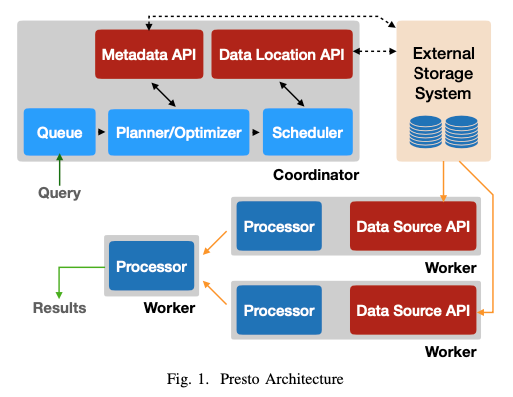
But we were talking about taking a user request and translating it into the commands of different data sources, so let’s jump into the worker which is responsible for fetching the data from a diverse set of data sources. To connect Presto to the rest of the world, you need to implement the Connector interface. It is the Connector which will helps Presto translate its internal representation to where the data is stored.
Presto provides a unified database feel for answering queries, but what if we could query different APIs as seamlessly as we do with Presto?
Querying (almost) everything
Enter Trustfall, a Rust-based project enabling users to query almost any data source, from APIs and databases to various files on disk — and even AI models.
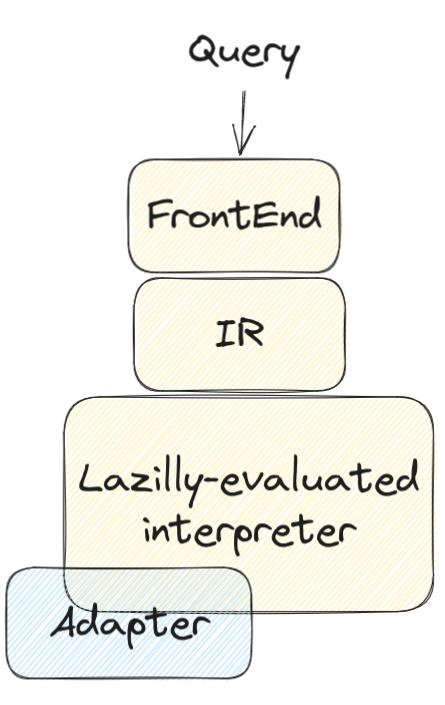
To connect Trustfall to diverse data sources, users need to define the schema and craft an adapter capable of communicating with the data source. As the user sends a query, the frontend compiles it into a lazily evaluated intermediate representation. During interpretation, the adapter is invoked to fetch the required data. For more insights, check out this informative talk.
This approach allows you to do very cool things such as cross-API queries. We can see a demo of a query responding “Which GitHub Actions are used in projects on the front page of HackerNews with >=10 points?” (which is available on the repo readme)

Why am I talking about Trustfall?
Well, it's an interesting project :). But I also got the chance to collaborate with it a little bit.